Встраивание в TCP/IP стек в ОС GNU/Linux
Автор: ilya![ilya [GuessWhat?] hackerdom.ru](./pictures/ilya_mail.gif)
Введение
Исследование протоколов - довольно интересное занятие. По-прежнему многие исследователи занимаются их оценкой и верификацией в различных ситуациях. Лично я столкнулся с необходимостью исследования протокола в первый год работы в ИММ УрО РАН [1]. Как бы это ни звучало банально, но это был TCP протокол. Причина, по которой я стал этим заниматься, следующая - необходимо было разобраться с сетью в одном из вычислительных кластеров. При передаче данных по протоколу TCP через 2-е 100 Мбит. сетевые карты одновременно (т.н. связывание каналов или по англ., bonding) наблюдался прирост скорости в два раза, и в тоже время на гигабитных карточках скорость не только не возрастала, но даже падала до 600 Мбит. в сек. Снифер ничего особого не показал. Да и вообще говоря, снифер не всегда может дать исчерпывающую информацию о происходящем в сети. С его помощью можно узнать о том, что произошло в сети и на основе этого попытаться понять, что происходило с протоколом. Но для этого как минимум необходимо точно себе представлять реализацию данного протокола в этой ОС. Согласитесь, это не легко. Да и надо ли это вообще, когда сама ОС и все протоколы прямо перед нами? К тому же, когда это open-source ОС, где нет ничего, что было бы скрыто от наших глаз.
Данная статья описывает один из двух (на данный момент мне известных!) способов встраивания в TCP/IP стек. Я это делал с целью узнать значение некоторых параметров и состояние протокольной машины TCP для конкретного соединения. Возможно, у вас будут на это другие причины :). Первый способ - это внести изменения в ядро ОС Linux, пересобрать его, перезагрузить машину и затем собирать необходимую информацию. И если пойти дальше, то можно даже включить это опцией при сборке ядра. Но этот способ примитивный, скучный, а значит, не доставляет никакого удовольствия. Второй - написать модуль к ядру, который бы подключался к TCP протоколу и выводил всю необходимую информацию. Он немного сложнее первого, но значительно интереснее, поверьте! Вот его мы и разберем.
В связи с тем, что изменения в ядро ОС Linux вносятся довольно часто, трудно написать пример кода, который бы работал на многих ядрах сразу. По этой причине, в этой статье описан пример встраивания в TCP стек в ядро ОС Linux версии 2.6.12. Также, в приложении можно найти код для версии ядра 2.6.18 (спасибо VenROCK’у, заставил!).
Сетевая подсистема ОС GNU/Linux
Начнем, пожалуй, с того, как в ОС Linux представлен сетевой стек. Для работы с сетью ОС Linux в основном используется 2-е структуры. Первая - это sk_buff, описывает пакет с содержимым и хранит служебную информацию, например, для какого сокета адресован данный пакет, когда он был создан, указатели на заголовки (Ethernet, IP, TCP..), размер пакета, с какого интерфейса пакет был получен или через какой его необходимо отправить и т.д. Некоторые из этих полей задаются в момент создания пакета, другие же - в процессе. Например, при отправке пакета структура sk_buff изначально содержит ссылку на сокет, а при получении пакета из сети - NULL, и это поле заполняется в процессе. Правда, некоторые поля могут оставаться пустыми на протяжении всего процесса существования, в зависимости от протокола.
Как только у ОС появляется необходимость работать с сетевым пакетом - это sk_buff. Она создается в тот момент, когда система получила пакет из сети, или когда ей необходимо сформировать новый для отправки. По этой причине в сетевом стеке практически каждая функция получает эту структуру в качестве параметра. Основное её назначение - дать простой и эффективный способ работы с пакетом на всех сетевых уровнях сетевого стека (см. рис. 1). Структура sk_buff представляет собой управляющую структуру с присоединенным блоком памяти, в котором находится пакет [2]. Таким образом, изменяя переменные в структуре, мы изменяем содержимое пакета или служебную информацию о нем.
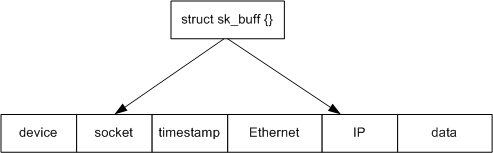
Рис. 1. структура sk_buff
Ниже представлена основная часть этой структуры.
struct sk_buff {
/* Первые две записи должны быть первыми. */
struct sk_buff *next;
struct sk_buff *prev;
struct sk_buff_head *list;
struct sock *sk;
struct timeval stamp;
struct net_device *dev;
struct net_device *input_dev;
struct net_device *real_dev;
/*
* Секция транспортного уровня, указывает на
* соответствующий протокол, такой как TCP, UDP, ICMP и т.д.
*/
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
} h;
/* Секция сетевого уровня */
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh;
/* Указатель на заголовок канального уровня, например, Ethernet. */
union {
unsigned char *raw;
} mac;
/*
* Остальная часть структуры содержит сопутствующую информацию о пакете.
* Длину, тип пакета, контрольную сумму и т.д.
*/
unsigned int len,
data_len,
mac_len,
csum;
unsigned short protocol,
security;
…
Более подробное её описание можно найти в исходных текстах ядра Linux: include/linux/skbuff.h.
Вторая структура, с которой необходимо познакомится - это sock, содержит информацию о состоянии сокета (connected, unconnected…), его тип (SOCK_STREAM, SOCK_DGRAM, SOCK_RAW), используемый протокол (TCP, UDP, IPPROTO_RAW …), размер буфера для приема и отправки пакетов, указатели на область памяти, где расположены буферы для приема и отправки пакетов, и т.д. Она создается и заполняется в момент, когда пользователь делает системный вызов socket. Ниже представлен кусок этой структуры с некоторыми комментариями.
struct sock {
/*
* Now struct tcp_tw_bucket also uses sock_common, so please just
* don't add nothing before this first member (__sk_common) --acme
*/
struct sock_common __sk_common;
#define sk_family __sk_common.skc_family /* Семейство протокола */
#define sk_state __sk_common.skc_state /* Состояние */
#define sk_reuse __sk_common.skc_reuse
#define sk_bound_dev_if __sk_common.skc_bound_dev_if
#define sk_node __sk_common.skc_node
#define sk_bind_node __sk_common.skc_bind_node
#define sk_refcnt __sk_common.skc_refcnt
unsigned char sk_shutdown : 2,
sk_no_check : 2,
sk_userlocks : 4;
unsigned char sk_protocol; /* Протокол */
unsigned short sk_type; /* Тип протокола */
int sk_rcvbuf; /* Размер буфера для приема */
socket_lock_t sk_lock;
wait_queue_head_t *sk_sleep; /* Очередь для ожидания */
struct dst_entry *sk_dst_cache;
struct xfrm_policy *sk_policy[2];
rwlock_t sk_dst_lock;
atomic_t sk_rmem_alloc;
atomic_t sk_wmem_alloc;
atomic_t sk_omem_alloc;
struct sk_buff_head sk_receive_queue; /* Очередь для входящих пакетов */
struct sk_buff_head sk_write_queue; /* Очередь для исходящих пакетов */
int sk_wmem_queued;
int sk_forward_alloc;
unsigned int sk_allocation;
int sk_sndbuf; /* Размер буфера для отправки */
int sk_route_caps;
int sk_hashent;
unsigned long sk_flags; /* Флаги :) */
unsigned long sk_lingertime;
…
Её полное описание можно найти в include/net/sock.h.
Имея в своем распоряжении эти две структуры (struct sk_buff и struct sock), можно принимать и отправлять пакеты, доставлять информацию от сетевого интерфейса к пользовательскому приложению и наоборот. Но структура sock описывает только общие вещи. Например, она не содержит ожидаемый номер последовательности TCP сегмента и многих других полезных вещей. Для этих целей служат другие структуры.
Каждый протокол имеет свою структуру для хранения необходимой ему информации. Например, для TCP эта структура называется tcp_sock, для UDP - udp_sock, продолжите сами :). Все они наследуют структуру sock, правда, не всегда напрямую, как это в случае с tcp_sock (см. рис 2). Все самое интересное о работе протокола можно найти в этих структурах - его состояние, таймауты, номер последовательности ожидаемого пакета, и много другой специфической информации. Таким образом, самый лучший способ узнать, что происходит с протокольной машиной TCP - это считывать данные из структуры tcp_sock.

Рис. 2. Наследование структуры sock
Доступ к структуре tcp_sock
Перед тем как начать поиск, необходимо выяснить, что именно мы хотим обнаружить? Как было описано выше, tcp_sock наследует структуру sock, вот почему сначала нам необходимо найти нужный сокет, а по нему мы сможем получить доступ к tcp_sock. В ОС Linux для быстрого поиска TCP и UDP сокета их хранят в специальной хеш таблице. Место их расположения определяется путем вычисления некоторого хеша на основе 4-х параметров: адрес отправителя, порт отправителя, адрес получателя и порт получателя. Ну что же, логично! После определения его места расположения сокет можно извлечь. В самом TCP протоколе операция по обнаружению и извлечению сокета описана в функции __tcp_v4_lookup_established, которая находится в файле net/ipv4/tcp_ipv4.c. Вот её исходный код:
486 static inline struct sock *__tcp_v4_lookup_established(u32 saddr, u16 sport,
487 u32 daddr, u16 hnum,
488 int dif)
489 {
490 struct tcp_ehash_bucket *head;
491 TCP_V4_ADDR_COOKIE(acookie, saddr, daddr)
492 __u32 ports = TCP_COMBINED_PORTS(sport, hnum);
493 struct sock *sk;
494 struct hlist_node *node;
495 /* Optimize here for direct hit, only listening connections can
496 * have wildcards anyways.
497 */
498 int hash = tcp_hashfn(daddr, hnum, saddr, sport);
499 head = &tcp_ehash[hash];
500 read_lock(&head->lock);
501 sk_for_each(sk, node, &head->chain) {
502 if (TCP_IPV4_MATCH(sk, acookie, saddr, daddr, ports, dif))
503 goto hit; /* You sunk my battleship! */
504 }
505
506 /* Must check for a TIME_WAIT'er before going to listener hash. */
507 sk_for_each(sk, node, &(head + tcp_ehash_size)->chain) {
508 if (TCP_IPV4_TW_MATCH(sk, acookie, saddr, daddr, ports, dif))
509 goto hit;
510 }
511 sk = NULL;
512 out:
513 read_unlock(&head->lock);
514 return sk;
515 hit:
516 sock_hold(sk);
517 goto out;
518 }
Высчитывание хеша производится в 498 строке путем вызова функции tcp_hashfn с 4-мя параметрами: локальный адрес, локальный порт, удаленный адрес, удаленный порт.
498 int hash = tcp_hashfn(daddr, hnum, saddr, sport);
А затем извлекается сам сокет:
499 head = &tcp_ehash[hash];
500 read_lock(&head->lock);
501 sk_for_each(sk, node, &head->chain) {
502 if (TCP_IPV4_MATCH(sk, acookie, saddr, daddr, ports, dif))
503 goto hit; /* You sunk my battleship! */
504 }
Функция, которая производит расчет хеша, называется tcp_hashfn, начиная с версии ядра 2.6.18 она стала называться inet_ehashfn() и её перенесли в заголовочный файл, так что теперь нет нужды описывать её в своем коде. Но мы пишем код под 2.6.12, так что придется нам посмотреть, где и как описывается эта функция. Исходный код её так же можно подсмотреть в net/ipv4/tcp_ipv4.c.
107 static __inline__ int tcp_hashfn(__u32 laddr, __u16 lport,
108 __u32 faddr, __u16 fport)
109 {
110 int h = (laddr ^ lport) ^ (faddr ^ fport);
111 h ^= h >> 16;
112 h ^= h >> 8;
113 return h & (tcp_ehash_size - 1);
114 }
Тут стоит сделать одно важное замечание - локальный порт передается в обычном виде (LittleEndian), а порт назначения в сетевом порядке байт (BigEndian), т.е. необходимо выполнить htons(dest). После извлечения сокета доступ к структуре tcp_sock производится очень просто:
struct tcp_sock *tp; tp=(struct tcp_sock *)sk;
Ну а дальше, что вашей душе угодно.
В приложении можно найти исходный код для ядра 2.6.12 и 2.6.18. Используя NetFilter[4], модуль перехватывает все входящие пакеты и анализирует их. Если этот пакет относится к искомому соединению, тогда мы вычисляем хеш, получаем указатель на сокет, извлекаем его, и через него получаем доступ к tcp_sock. Если не понятно, читайте все сначала :).
Примечание
Помимо различий в самой ветке 2.6., существует несколько отличий при подключении к TCP стеку в 2.4. Но все отличие заключается в другом названии структур и немного отличный способ извлечения сокета. Принцип остается тем же.
Автор выражает благодарность за помощь при подготовке данной статьи Игумнову А.С. и Шарфу С.В. из ИММ УрО РАН.
Список литературы
- Эффективность связывания гигабитных каналов в вычислительных кластерах.
- A Map of the Networking Code in Linux Kernel 2.4.20 - googling
- Network Buffers And Memory Management
- В этом же номере журнала.
- Linux kernel